Scraping reviews of my favourite book on Amazon
Build a web scraper with Python in less than 5 minutes.


I recently started reading a book titled "A Short History of Nearly Everything" by Bill Bryson.
This book lives up to its name. It literally takes the reader through a short history of everything that has taken place in the world, starting with the creation of the universe.
I never really had much interest in science in the past. I found the subject to be quite dry and boring in school.
Reading this book made me look at science with a different perspective. It answered questions about the universe - questions I didn't even know I had, emphasizing major occurrences due to which we are here today.
Fun fact in the book: The tongue twister "she sells sea shells by the sea shore" is actually about a girl named Mary Anning who discovered fossils and made money by selling them ever since she was 12 years old.
I was hooked onto this book from the very first chapter, and went online to read other people's opinion on it.
After reading multiple book reviews, I had an idea.
I decided to build a web scraper to collect and store all these reviews.
Then when I had the time, I would perform an analysis on these reviews. Maybe I'd even build a sentiment analysis model to distinguish between positive and negative reviews.
In this tutorial, I will walk you through all the steps I took to scrape the book reviews on Amazon. I will use two Python libraries to do this - BeautifulSoup and Selenium.
I will provide all the code I used. You can use them as starter code for any web scraping project of your own in the future.
Pre-requisites
To follow along to this web scraping tutorial, you need to have a Python IDE installed on your computer.
We will be using Pandas, Selenium, and BeautifulSoup in this analysis, so make sure you have them installed before you start.
Step 1
First, let's go to the page we want to scrape and take a look at its layout:
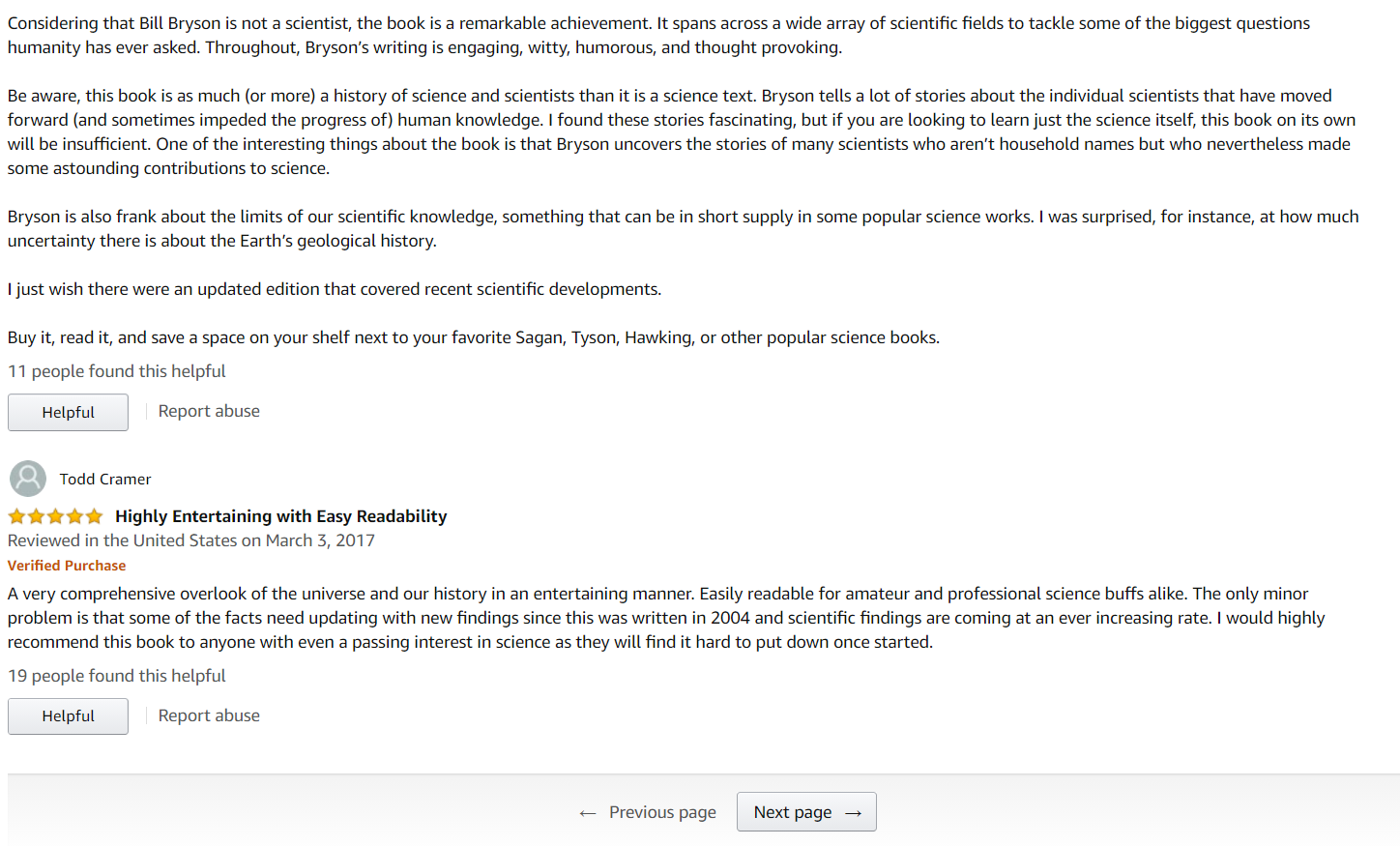
Notice that there are about ten reviews on each page.
The number of pages we choose to scrape depends on how many reviews we want to collect.
In this tutorial, we can start out with the first 500 reviews (50 pages).
Step 2
First, import the following packages:
import pandas as pd
import numpy as np
from pprint import pprint
import io
import os
from bs4 import BeautifulSoup
import requests,json, re
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManagerStep 3
Now, we can use the Selenium web driver to automatically download the first 50 pages of the site that we want to scrape.
First, we can create a folder to save the HTML files in. Then, we define the path in Python.
# path you want to save the HTML files in
path = '\amazon_scraping'Next, we can loop through the number of pages we want to scrape. In our case, its page 1 to page 51.
Then, we can create a webdriver object, get all the pages we want to scrape and save the pages in our directory.
for i in range(1,51) :
driver = webdriver.Chrome(ChromeDriverManager().install())
url = 'https://www.amazon.com/Short-History-Nearly-Everything/product-
reviews/B0000U7N00/ref=cm_cr_getr_d_paging_btm_prev_1? ie=UTF8&reviewerType=all_reviews&pageNumber='+str(i)
driver.get(url)
time.sleep(1)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# save all 50 files in your path
with io.open(path+"amazon_page_"+str(i)+".html", "w", encoding="utf-8") as f:
f.write(html)After saving all 50 pages into our local directory, we can start with the web scraping.
Step 4
Lets start with scraping one web page first:

This is a sample review of the book on Amazon's webpage.
To scrape it, we need to look at the HTML structure of the page. Right click on the review and click on "inspect."
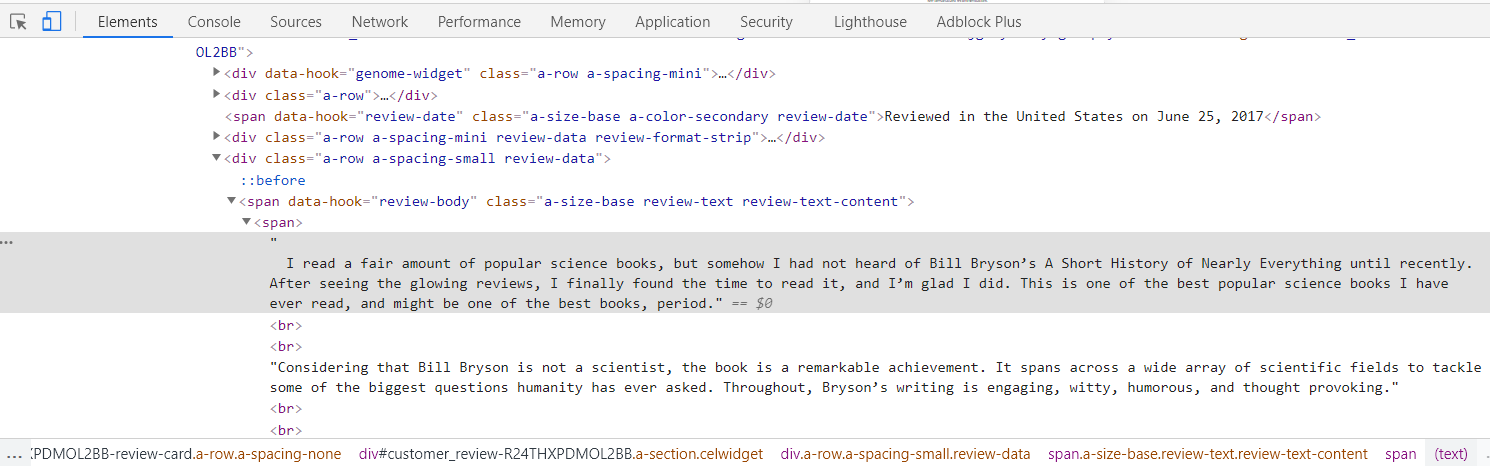
We can see that all the review text is wrapped in a span class called "a-size-base review-text review-text-content."
This is the element we need to extract when scraping reviews.
To do this, you first need to open one of the pages you saved previously:
# open the first page you saved
file = open(path+'amazon_page_1'+str(pages)+'.html',encoding='utf-8')
Then, create a BeautifulSoup object to collect all the HTML code of that page:
soup = BeautifulSoup(file, 'html.parser')Now, grab the 'span' class we found earlier using BeautifulSoup:
for i in soup.find('div',{'id':'cm_cr-review_list'}):
review = i.find('span',{'class':'a-size-base review-text review-text- content'})
if review is not None:
print(review.text)This code will render output that looks like this (it should show you around 10 reviews since you are only scraping the first page):

Great!
The code works, and we have grabbed all the reviews from the first page and printed them out.
Now, we just need to loop through all 50 pages and do the same thing.
Step 5
Looping through all the pages and collecting reviews:
# create an empty list
rev = []
# loop through all 50 pages
for pages in range(1,51):
file = open('amazon_page_'+str(pages)+'.html',encoding='utf-8')
soup = BeautifulSoup(file, 'html.parser')
# find the reviews
for i in soup.find('div',{'id':'cm_cr-review_list'}):
review = i.find('span',{'class':'a-size-base review-text review-text-content'})
# append reviews to list
if review is not None:
rev.append(review.text)
else:
rev.append('-1')That's all!
Once we're done running this block of code, all the saved reviews will be saved in the list 'rev' that we initialized.
Now, all we need to do is turn that list into a Pandas data frame:
final_df = pd.DataFrame({'Reviews':rev})We can take a look at the head of the data frame:

All the reviews we scraped are in there.
The data frame will have around 600 rows, but if you drop the '-1' character, you'd get around 500 rows.
If you want to collect more reviews, all you need to do is scrape more pages.
Complete Code
import pandas as pd
import numpy as np
from pprint import pprint
import io
import os
from bs4 import BeautifulSoup
import requests,json, re
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
path = '\amazon_scraping'
for i in range(1,51) :
driver = webdriver.Chrome(ChromeDriverManager().install())
url = 'https://www.amazon.com/Short-History-Nearly-Everything/product-reviews/B0000U7N00/ref=cm_cr_getr_d_paging_btm_prev_1?ie=UTF8&reviewerType=all_reviews&pageNumber='+str(i)
driver.get(url)
time.sleep(1)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
with io.open(path+"amazon_page_"+str(i)+".html", "w", encoding="utf-8") as f:
f.write(html)
rev = []
for pages in range(1,51):
file = open(path+'amazon_page_'+str(pages)+'.html',encoding='utf-8')
soup = BeautifulSoup(file, 'html.parser')
for i in soup.find('div',{'id':'cm_cr-review_list'}):
review = i.find('span',{'class':'a-size-base review-text review-text-content'})
if review is not None:
rev.append(review.text)
else:
rev.append('-1')
print(pages)
final_df = pd.DataFrame({'Reviews':rev})That's it for this tutorial!
I hope you enjoyed coding along, and took away something useful from here.
You can use this tutorial as a guide to any web scraping project in the future. If you want to scrape different products on Amazon, you can use this as starter code.
If you've made it this far, thank you for reading!