The Bias Variance Trade-off


In this article, I'm going to break down an important topic in machine learning called the bias-variance trade-off.
Before going into detail about what the terms bias and variance mean, it is important to understand two other concepts: overfitting and underfitting.
Overfitting vs Underfitting
When a model fits very well to training data but performs poorly on test data, the model is said to be overfitting.
When a model fits poorly on both train and test data, then it is said to be underfitting.
Lets take a look at an example:
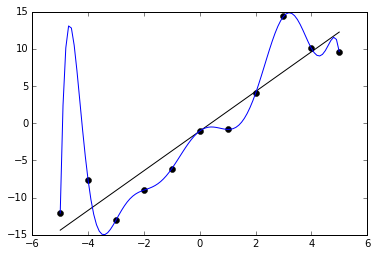
The picture above is a visual representation of two functions, and their fit onto training data.
The first function is represented by a blue line.
It is a polynomial function, and passes through every single point in the training dataset. This function fits perfectly onto the training dataset. In fact, the accuracy of this model on training data will be 100%.
Now, lets take a look at the second function represented by the black line.
This is a linear function, and does not pass through all the points in the training dataset. It only passes through two points, and doesn't seem to be a very good fit to the training data. The accuracy of this model on the training data should be a lot lower. For the sake of this tutorial, lets say that it is around 60%.
From this image alone, can you tell which model is a better fit?
Is it the polynomial function represented by the blue line or the linear function represented by the black line?
The answer is neither.
Both models are terrible.
The problem with the first model:
The first model represented by the blue line performs really well on the training data.
It makes an accurate prediction on all the data points in the training set.
However, this model will be unable to generalize to a different set of data.
When presented with new data it has never seen before, the model will make inaccurate predictions on a lot of new data points. This will result in low test accuracy.
If a machine learning model has high training accuracy and low test accuracy, then the model is overfitting.
Although the model performs well on the training set with an accuracy of 100%, this model will not generalize well outside of this domain, and the test accuracy will be a lot lower.
The problem with the second model:
The second model has the opposite problem.
While the first model is very complex and fits really well onto the training data, the second model lacks complexity.
It doesn't capture all the patterns in the training data, and is a poor fit. It is too simple.
This model is underfitting.
What is an ideal model?
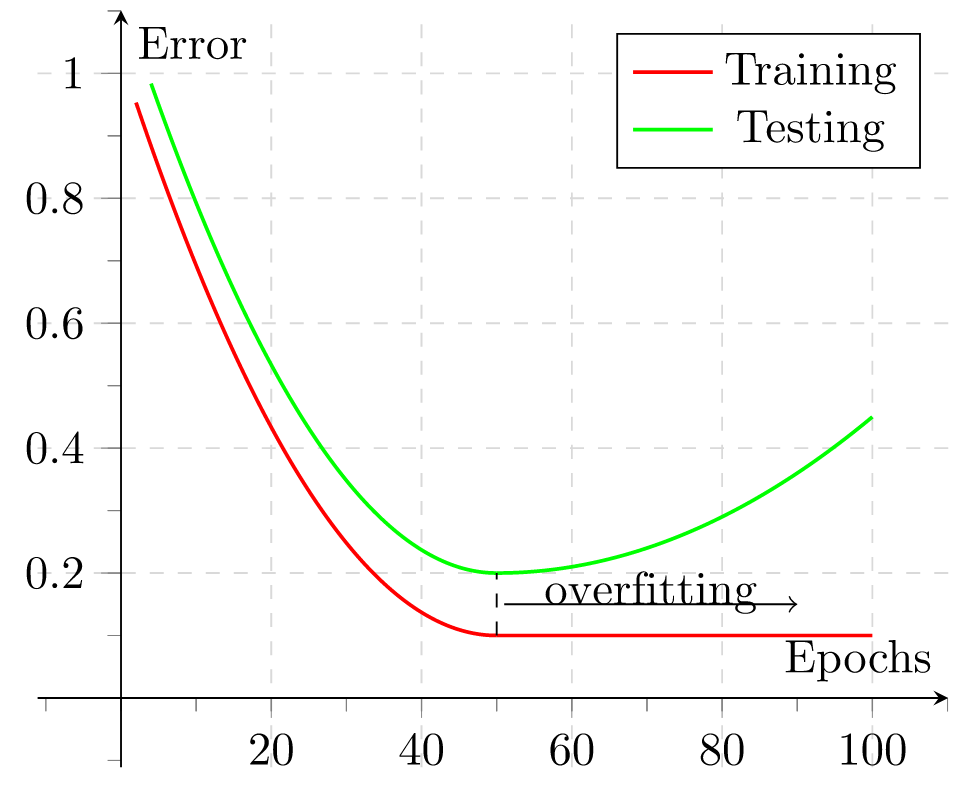
An ideal model is one that has low training and test error. This means that the model should neither underfit nor overfit.
Take a look at the diagram above.
The red line represents the model's performance on the training data.
As we increase the number of epochs (or increase model complexity), the model's error starts to go down on the training data.
The error almost goes down to zero, meaning that it is almost a perfect fit to the training data.
Now, look at the green line. This line represents the model's performance on test data. Notice that as we increase model complexity, the test error starts to go down at first.
Then, something strange happens.
After around 50 epochs, the test error starts to go up, while the training error continues to decrease.
This is an indication that the model is beginning to overfit on the training set.
It starts to perform better and better on training data, but performance deteriorates on test data.
By taking a look at the visualization above, we can conclude that the ideal model complexity as at 50 epochs. The model isn't overfitting, neither is it underfitting. This is the ideal number of epochs to use when building the model.
Bias
Every machine learning model needs to make some assumptions about the data it is training on. A model with low bias will make fewer assumptions about the target function, and will perform better on training data.
A machine learning model is good if it has lower bias. This means that it effectively captures all the relationships in the feature space, and is able to fit well on training data.
A model with low bias will perform very well on the training set, and will have low training error.
Looking back at the image we saw previously:
The polynomial function fits very well onto the training data and has low bias. It doesn't make many assumptions about the target variable, and is able to capture the relationship between the features and target.
On the other hand, the linear function does not fit well onto the training data, and has high bias.
Remember - Simple models (like linear models) have higher bias. They don't fit very well onto the training set.
More complex functions (like the polynomial function above) tend to have lower bias, and fit very well on training data.
Variance
A model's variance is the amount by which the its prediction would vary if a different training set was used.
Ideally, even if we use different training sets, the model's predictions should not vary too much.
If the model has picked up on underlying patterns and is able to correctly identify relationships between variables, then its variance should be low.
To simplify your understanding of variance, think of it this way:
- If a model is fit onto a training dataset, it should not just perform well on that dataset.
- It should also be able to pick up relationships between variables, and perform well even if the training dataset changes.
- Essentially, what we're looking at when we measure variance is the model's ability to generalize to data outside of the data it was trained on.
Take a look at the overfitting vs underfitting diagram again.
Notice that the polynomial function fits very well onto the training data, but wouldn't be able to generalize. If the training dataset was changed, the model's performance would decrease. This means that the model has high variance.
On the other hand, take a look at the linear function. This function does not fit too well onto the training data. However, if we replaced the training dataset, the performance of the model wouldn't change much. It is able to generalize to other datasets because it is simple. This model has low variance.
The Bias-Variance Trade-off
An ideal machine learning model should have low bias and low variance. This model should perform well on the training dataset by identifying relationships between variables and making fewer assumptions.
At the same time, the model needs to be able to generalize, and should perform well on data that its never seen before.
As the bias of the model increases, its variance decreases. As the model starts to perform better on training data, its performance on test data starts to deteriorate.
There is a trade-off between generalization and specialization. This is called the bias-variance trade-off.
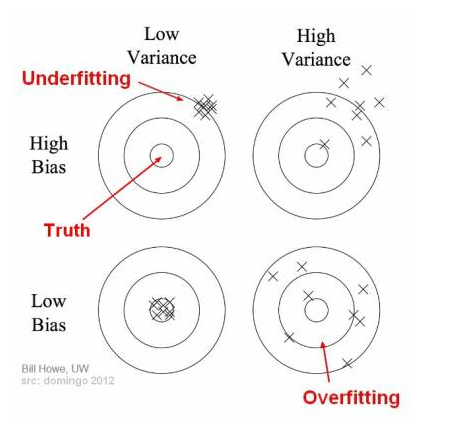
There are four different scenarios in the diagram above:
High Bias and Low Variance
A model that has high bias and low variance is underfitting. This model doesn't fit well enough to the training data, and is unable to capture underlying relationships between variables. However, its performance doesn't change much with different training datasets since it is able to generalize well.
Simple models like linear regression tend to have high bias and low variance.
High Bias and High Variance
A model that has both high bias and high variance makes a lot of assumptions about the target variable, and doesn't perform well on the training dataset. Its performance also varies a lot with different training datasets.
Low Bias and High Variance
A model that has low bias and high variance is overfitting. This model fits very well to the training data, but is unable to generalize. It will not perform well on a test set or different training sets.
Models like decision trees (without implementing early stopping mechanisms) tend to have low bias and high variance.
Low Bias and Low Variance
An ideal model has low bias and low variance. As mentioned above, this is a model that fits well onto the training data, but is also able to generalize and perform well on other datasets.
That's all!
If you made it till here, thanks for reading. I hope you learnt something new from this tutorial.
To learn more about the bias-variance trade-off and other machine learning concepts, I suggest reading this free e-book called Elements of Statistical Learning.